RL-Enhanced 6DOF Rocket Landing
A reusable-booster landing benchmark with variable mass, quaternion attitude dynamics, thrust-vector control, classical baselines, flat PPO, hierarchical PPO, and hybrid residual reinforcement learning. Goal was to determine if a learned RL policy can reduce rocket landing dynamics successfully.
Scope boundary: this is a research simulator and controller benchmark, not an exact vehicle, mission, aerodynamic, or flight-software reconstruction.
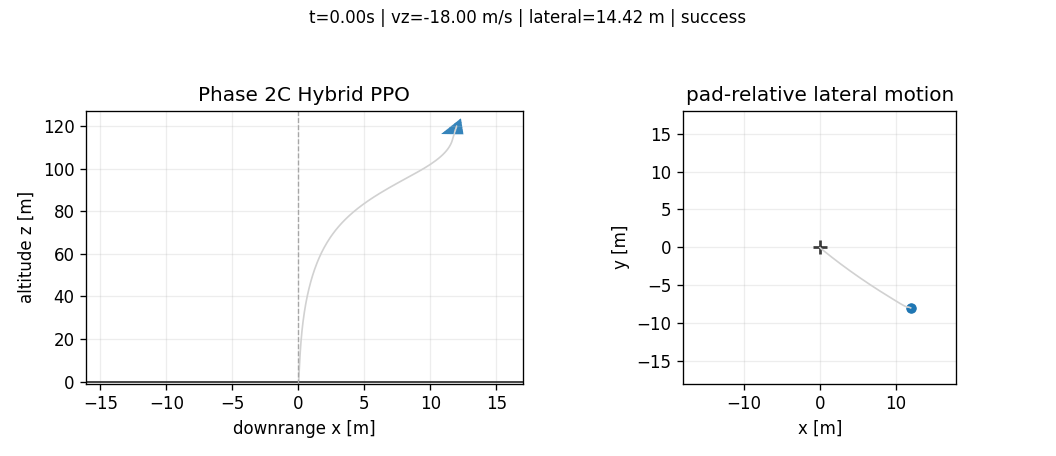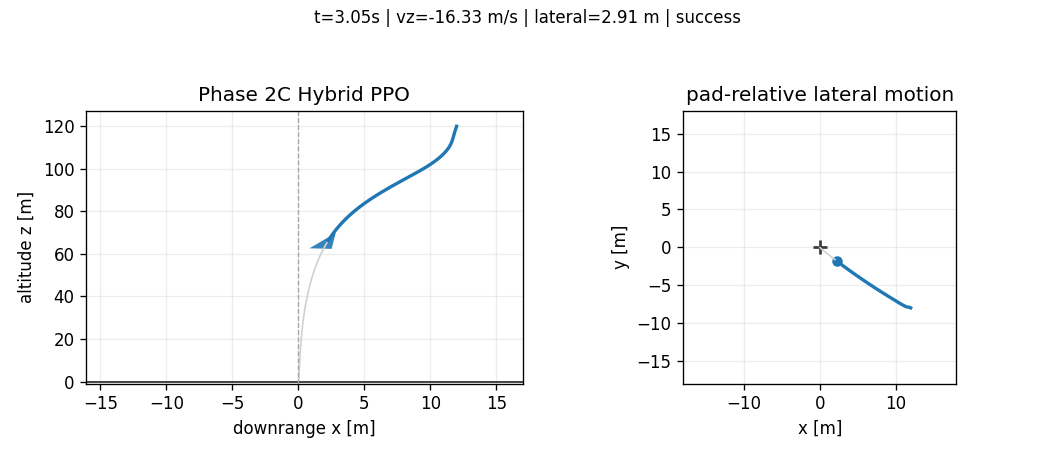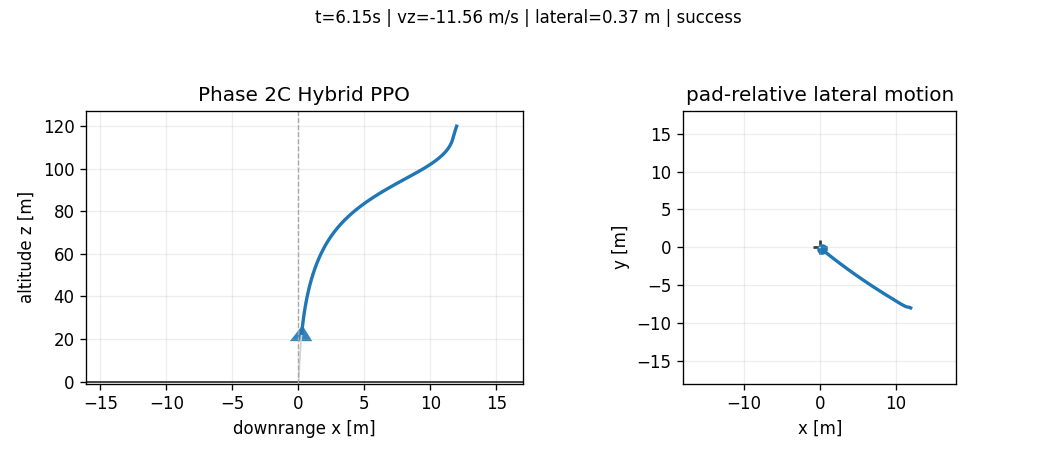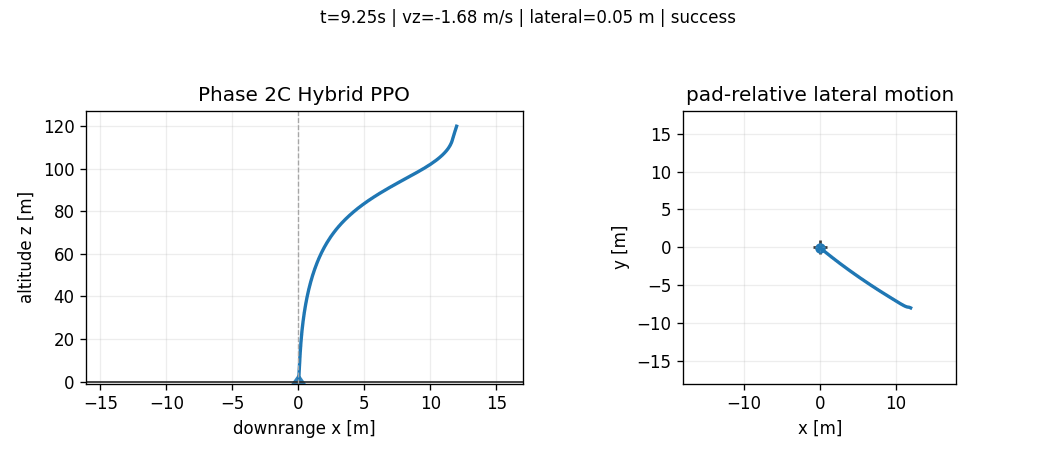
Abstract
Reusable booster landing is a useful control problem because it is simple to state and difficult to make honest. The vehicle must remove vertical energy, arrest lateral motion, maintain attitude, obey actuator limits, and do all of that while its mass changes during powered descent. A reinforcement-learning benchmark that removes variable mass, attitude dynamics, disturbances, or lateral-attitude coupling can look impressive while avoiding the hard part of the problem.
This article presents the current state of a Falcon 9-inspired 6DOF landing simulator and controller stack. The simulator uses a locally flat inertial frame, scalar-first quaternions, variable mass, thrust-vector control, simplified aerodynamics, an ISA-style atmosphere, and modular disturbances. The controller sequence is deliberately conservative: first a gain-scheduled LQR baseline, then a flat PPO baseline, then a pure hierarchical PPO controller with separated throttle and TVC policies, and finally a hybrid residual PPO controller that learns bounded corrections around a classical stabilizing prior.
The central empirical result is not that learned control simply dominates classical control. It does not. The Phase 1 gain-scheduled LQR is strong and reliable on the nominal and Monte Carlo evaluations. Flat PPO learns partial descent behavior but fails the coupled touchdown criteria. Pure hierarchy improves interpretability but exposes a frozen-policy coordination problem. Hybrid residual PPO becomes useful only after the learned policy is given the right job: correct a structured classical prior and operate inside a physically meaningful throttle-prior design.
All figures in this article are generated from saved CSV/JSON artifacts. The GIFs visualize saved trajectories, not newly simulated or hand-edited outcomes. The purpose is to make the benchmark falsifiable: every claim should point back to a trajectory, a metric file, or a documented design decision.
Why this matters
The useful contribution is not a claim that reinforcement learning has "solved rocket landing." The contribution is a compact benchmark story where classical control, flat RL, hierarchical RL, and residual RL are all forced through the same 6DOF touchdown metrics. That makes the failures comparable instead of anecdotal.
First, the simulator keeps the control-relevant structure that easy benchmarks often remove: variable mass, quaternion attitude, lateral-attitude coupling, TVC limits, atmosphere, aerodynamic drag, and modular disturbances. Second, the controller ladder is intentionally conservative. A gain-scheduled LQR baseline is built first, then a flat PPO baseline, then a separated throttle/TVC hierarchy, and finally a hybrid residual controller around a classical prior.
The main finding is also narrower than a headline result. The learned controller becomes useful when PPO is no longer asked to own the whole landing problem. Phase 2C succeeds nominally because the residual policy inherits the lateral-attitude structure of LQR while the throttle channel is redesigned around terminal vertical energy. Once lateral error, horizontal speed, tilt, and angular rate are controlled, the hard variable is no longer "landing" in the abstract; it is whether the vehicle has enough altitude left to remove downward kinetic energy.
This project sits between powered-descent guidance, classical feedback control, and modern continuous-control reinforcement learning. Classical guidance and LQR-style controllers are strong because they encode structure: local linearization, controllability, actuator limits, and physically interpretable references. End-to-end RL is attractive because it can absorb nonlinear coupling and discovered corrections, but it is also very good at hiding failure modes behind a single return curve.
Hierarchical RL is the natural middle ground: split vertical energy from lateral-attitude control and train specialized policies. The Phase 2B results show why that idea is appealing and why it is not enough. The throttle policy can improve the vertical subproblem while still producing a frozen schedule that makes the full 6DOF terminal regime brittle. Residual RL is the next step: keep the stabilizing structure, then learn bounded corrections where the model or baseline is imperfect.
In that sense, the closest research question is not "can PPO beat LQR?" It is "where should learning enter a safety-critical control stack so that it improves behavior without erasing auditability?" The answer in this benchmark is specific: learned residual TVC helps after LQR has stabilized the attitude channel, while terminal throttle behavior needs explicit energy and stopping-distance structure.
Simulator model
The simulator is built around a rigid-body state rather than a convenience state for learning. This matters because the controller should not be able to choose a throttle command without paying for propellant, or correct lateral motion without rotating the vehicle and inducing angular dynamics. The state tracks inertial position, inertial velocity, scalar-first quaternion attitude, body angular rates, and mass:
The inertial frame \(I\) is locally flat with \(+z_I\) upward. Gravity is therefore \(g_I=[0,0,-g]\). The body frame \(B\) uses \(+z_B\) as the longitudinal axis from engine toward nose. The identity quaternion means the vehicle is upright, so body \(+z_B\) aligns with inertial \(+z_I\). Quaternions map body-frame vectors into the inertial frame and are renormalized after each RK4 integration step:
The translational model includes gravity, thrust, aerodynamic drag, and wind-relative velocity. The rotational model includes TVC moments from an engine below the center of mass and simple aerodynamic damping. In compact form:
Thrust is generated in the body frame and rotated into the inertial frame. With zero gimbal, thrust points along body \(+z_B\). A pitch gimbal tilts thrust toward body \(+x_B\), and a yaw gimbal tilts thrust toward body \(+y_B\). The engine position is below the center of mass, so the TVC moment is the cross product \(M_{TVC,B}=r_{engine,B}\times F_{thrust,B}\). That single centered engine produces pitch and roll authority through off-axis thrust, but it does not create direct body-\(z\) yaw torque. This is why yaw is measured and reported while being excluded from pass/fail success criteria.
Variable mass is not a realism flourish; it changes the control problem. The same throttle fraction produces different acceleration as the vehicle burns propellant, and fuel use is itself an outcome. A controller that can land only by pretending mass is constant is solving a cleaner toy problem than the one this benchmark is meant to expose:
Aerodynamics are intentionally simplified but still present. Translational drag is computed from air-relative velocity, and the atmosphere uses a simple ISA-style density profile. Wind, thrust misalignment, and sensor noise are modular disturbances. The current Phase 1 classical controller uses true state feedback, but the disturbance interfaces are kept separate so later learned controllers and sensor models can use the same simulator path.
state = np.array([
x_m, y_m, z_m,
vx_mps, vy_mps, vz_mps,
qw, qx, qy, qz,
p_radps, q_radps, r_radps,
mass_kg,
])Integration uses fixed-step RK4. That choice is less glamorous than an adaptive integrator but better for a reproducible benchmark: controller update timing, logged trajectories, and timestep-sensitivity checks stay deterministic. The simulator terminates at touchdown when \(z_I \le 0\) after the first propagated step, and the shared metric extractor evaluates vertical touchdown speed, horizontal speed, lateral error, tilt, angular-rate norm, fuel exhaustion, divergence, and saturation fraction.
Environment Setup
The environment is deliberately not a high-fidelity launch-vehicle atmosphere. It is a compact, control-relevant world that makes the policy pay for the couplings we care about: changing air density, aerodynamic drag, wind-relative motion, time-varying gusts, and fixed thrust-direction bias. The point is not to recreate a specific flight day. The point is to stop the controller from succeeding only in a frictionless vacuum with a perfectly aligned engine.
The atmosphere is a simplified ISA-style model. Below the tropopause, density comes from the usual pressure-temperature relation; above it, the implementation switches to an exponential continuation. The aerodynamic model then computes drag from the vehicle velocity relative to the wind field:
Wind matters twice. It changes the aerodynamic force directly through \(v_{rel}\), and it creates lateral recovery demands that the TVC controller must remove before touchdown. Gusts are included because a steady crosswind is partly a bias-rejection problem, while a sinusoidal gust forces the controller to keep recovering as the disturbance changes over the descent.
Thrust misalignment is modeled as a persistent pitch/yaw gimbal bias added inside the propulsion model:
This is intentionally simple, but it tests an important thing: whether the controller can survive a persistent actuator-direction error without being told that the engine is perfectly aligned. Sensor noise is also implemented as a modular state-noise hook, but the current results are still mainly true-state-feedback results. That is why sensor noise is treated as future estimated-state work rather than a headline claim here.
| Level | Steady wind | Gust amplitude | Gust frequency | Thrust misalignment | Purpose |
|---|---|---|---|---|---|
| 0 | \((0,0,0)\,\text{m/s}\) | \((0,0,0)\,\text{m/s}\) | nominal scenario frequency | \((0,0)^\circ\) | clean controller check |
| 1 | \((2,0,0)\,\text{m/s}\) | \((0.5,0.25,0)\,\text{m/s}\) | nominal scenario frequency | \((0.20,-0.20)^\circ\) | mild robustness |
| 2 | \((5,0,0)\,\text{m/s}\) | \((1.0,0.5,0)\,\text{m/s}\) | nominal scenario frequency | \((0.50,-0.50)^\circ\) | moderate composite disturbance |
| 3 | \((8,0,0)\,\text{m/s}\) | \((1.5,0.75,0)\,\text{m/s}\) | nominal scenario frequency | \((1.00,-1.00)^\circ\) | stress test |
Classical baseline
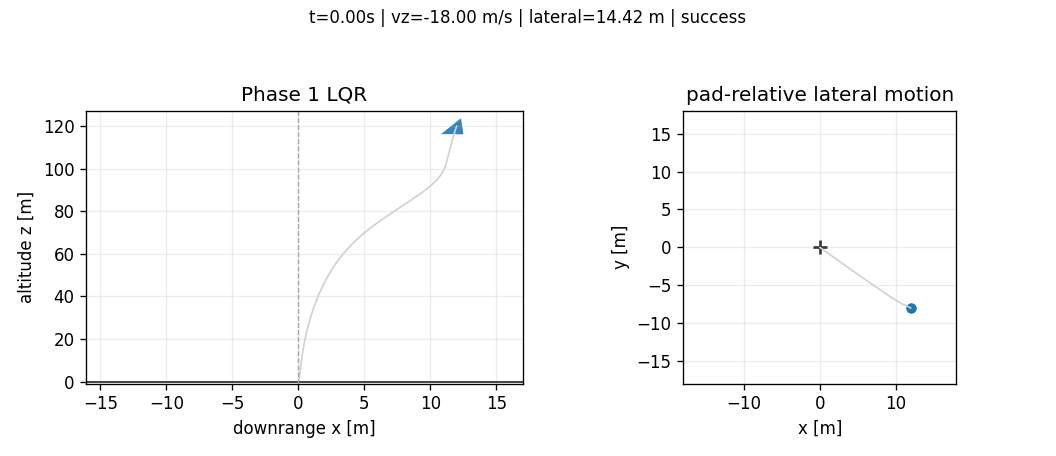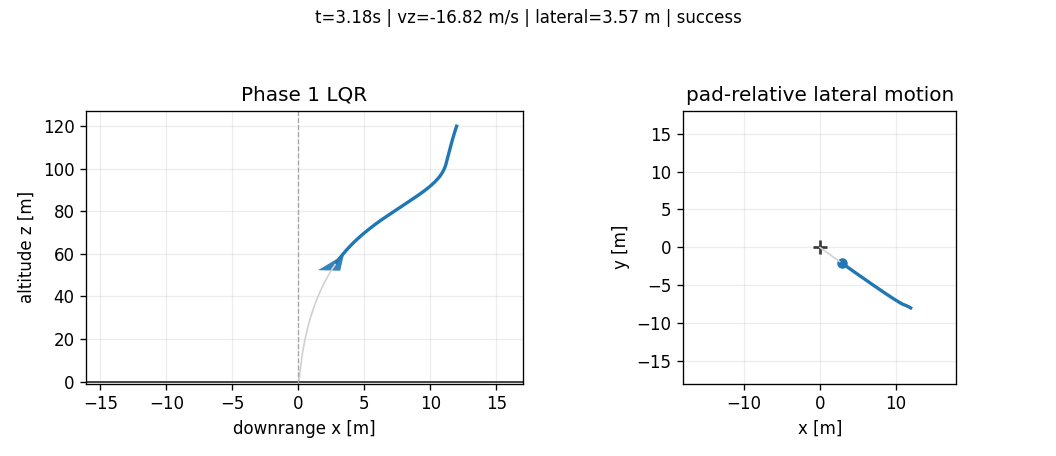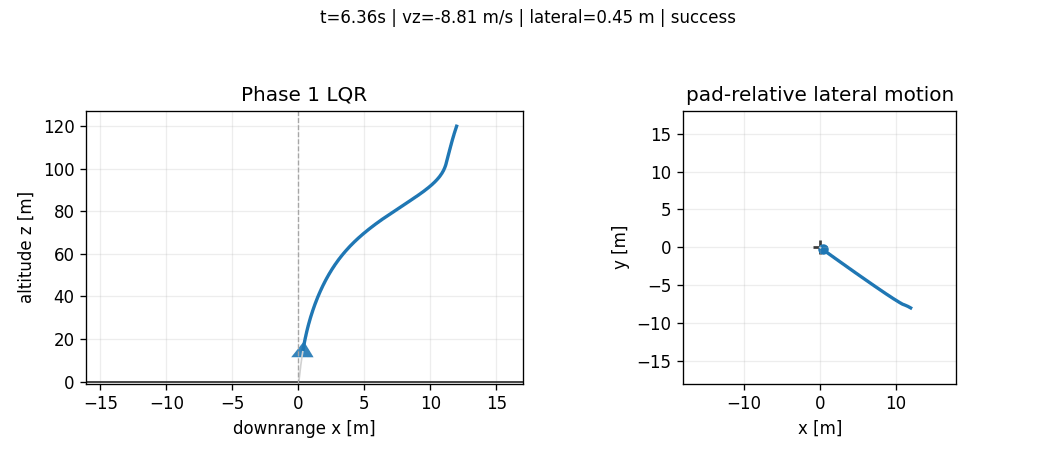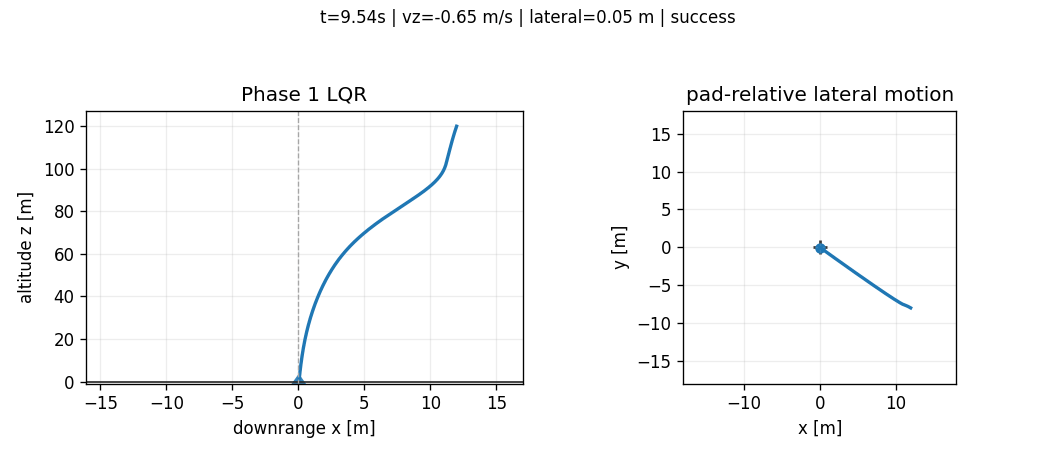
The first controller is not learned. That is an important methodological decision. A weak classical baseline would make any RL result look stronger than it is. The Phase 1 controller is a gain-scheduled hover-trim LQR that linearizes the upright landing problem around local hover-like dynamics and interpolates gains over a nominal mass grid. The public controller error state is a 12-vector:
The LQR does not track a full precomputed landing trajectory. Instead, the vertical channel tracks an altitude-dependent descent-rate reference. The reference is shaped by the same braking-energy idea used repeatedly later in the project:
This prevents the baseline from becoming a hover controller that simply tries to regulate \(z=0\) from high altitude. It descends aggressively when altitude is high and slows as touchdown approaches. Near upright hover, small pitch and yaw gimbal commands couple attitude into lateral acceleration. The implementation records the approximation directly in the controller notes:
The controller solves a Riccati problem on the controllable subset and schedules gains with mass. Yaw states remain in the public error vector because yaw is part of the full attitude state, but yaw feedback gains are zero under the current single-engine actuation model. This sounds like a narrow modeling detail, but it prevents a subtle overclaim: if the actuator cannot produce body-\(z\) torque, the controller should not be credited with yaw regulation.
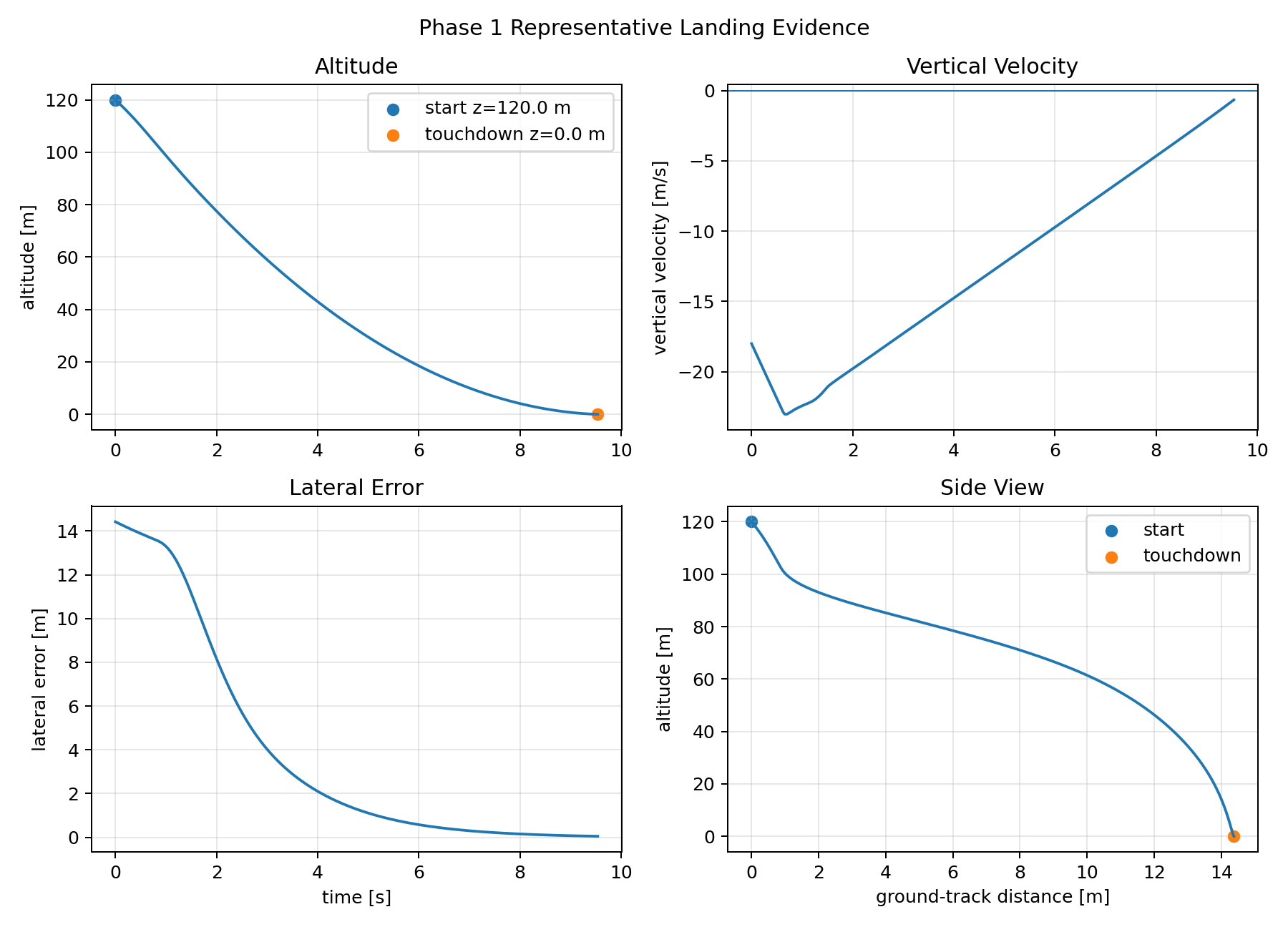
The important decision was not that LQR is "realistic enough." It is that a credible classical baseline prevents the RL comparison from becoming a victory lap over an obviously weak controller. In nominal evaluation, the LQR lands softly with small lateral error and low tilt. In the 500-episode-per-level Monte Carlo evaluation, it remains the most reliable controller. As a result, the controllers serves as a baseline to compare other learned controllers with.
RL formulation
The learned controllers are trained as episodic policies over the same simulator used by the classical baseline. The Markov decision process is
The transition kernel \(P\) is the RK4-integrated 6DOF dynamics with variable mass, atmosphere, aerodynamics, TVC, and the active disturbance configuration. The policy does not receive an invented low-dimensional "landing score." It receives normalized physical state features. The flat observation is a 14-vector:
PPO optimizes the clipped surrogate objective rather than directly differentiating through the simulator:
The flat Phase 2A reward is intentionally decomposed so failures can be diagnosed by term. With the default weights from the implementation, the dense reward is
On a failed touchdown, the metric penalty is not vague. It is the weighted sum
This calculation makes the flat-policy failure concrete. For the saved Phase 2A nominal rollout, the terminal metrics give approximately
Including the touchdown failure penalty adds another \(-180\), so the terminal event contributes roughly \(-539\) before considering the dense trajectory terms. The policy is not being rewarded for crashing; it is failing because the action interface and reward landscape still make the coupled terminal solution hard to discover.
| Phase | Policy input | Action output | Prior structure | Main failure | Next change |
|---|---|---|---|---|---|
| 2A Flat PPO | \(o_{14}\) | \([a_T,a_p,a_y]\) | None beyond hover-relative throttle centering | Joint touchdown constraints not solved | Separate vertical throttle from TVC |
| 2B Hierarchical PPO | \([h,v_z,\mu]\) for throttle; \(o_{14}\) plus coordination features for TVC | \(u_T\), then \([\delta_p,\delta_y]\) | Frozen learned throttle prior | Terminal coordination stayed brittle | Add LQR prior and bounded residual learning |
| 2C Hybrid residual PPO | \(o_{21}=o_{14}\) plus 5 coordination features plus 2 LQR prior gimbal features | Bounded TVC residual | LQR TVC prior plus learned/physics throttle priors | Vertical energy remained the binding constraint | Add energy assist and stopping-distance throttle floor |
How we judge a landing
A landing is counted as successful only if the final state satisfies all touchdown constraints. The criteria are intentionally stricter than "the vehicle reached the ground" because many policies learn to terminate while still being unusable as controllers:
The metric extractor also rejects fuel exhaustion, numerical divergence, excessive final altitude, and persistent actuator saturation. Yaw remains reported through attitude and angular-rate quantities, but direct yaw regulation is not part of the success criterion because the current single centered TVC engine is yaw-underactuated.
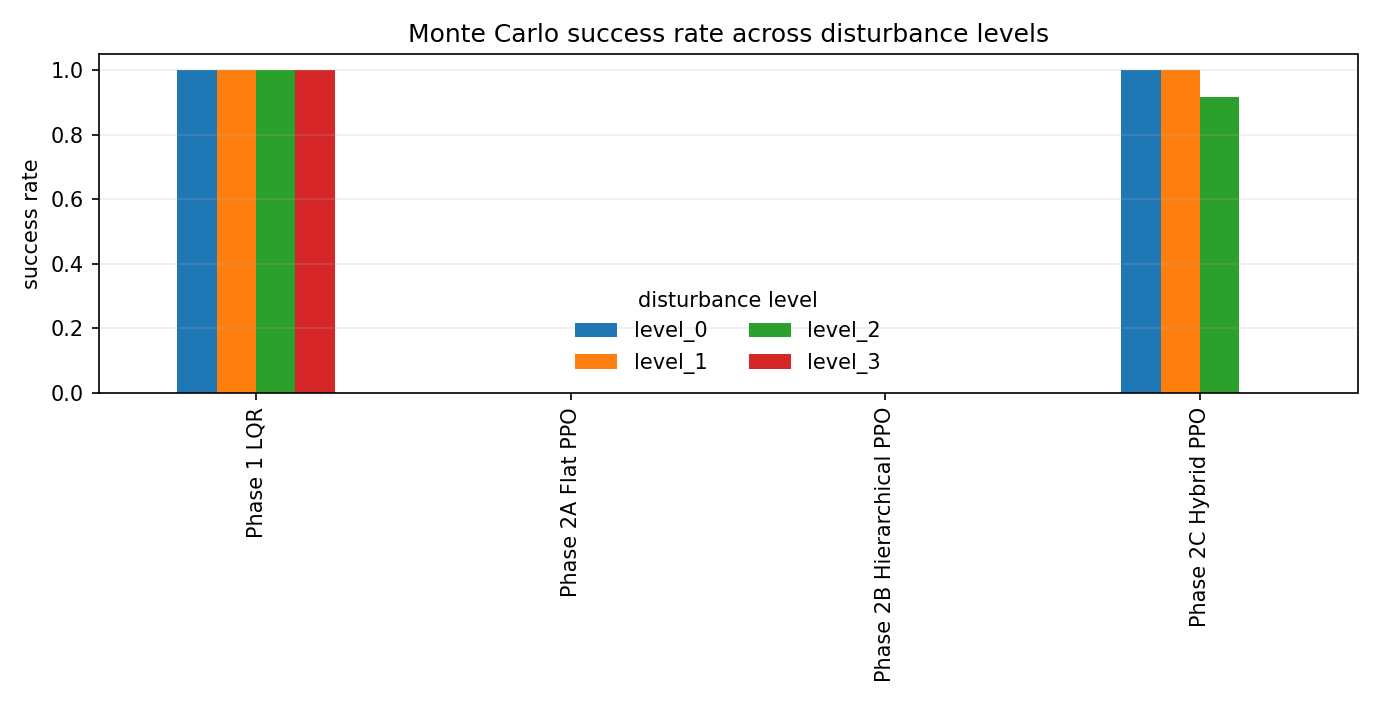
The evaluation has two layers. The nominal rollout asks whether a controller can satisfy the locked reference scenario. The Monte Carlo suite asks whether that behavior survives randomized composite disturbance levels. For each controller and disturbance level, the saved Phase 3 evaluation uses \(n=500\) episodes and reports the empirical success rate
This confidence interval is not a substitute for broader seed sweeps, but it prevents the table from pretending that \(458/500\) and \(500/500\) carry the same empirical meaning. It also keeps the LQR result honest: the classical baseline is not a ceremonial comparator. It is the controller the learned methods must earn the right to be compared against.
The result
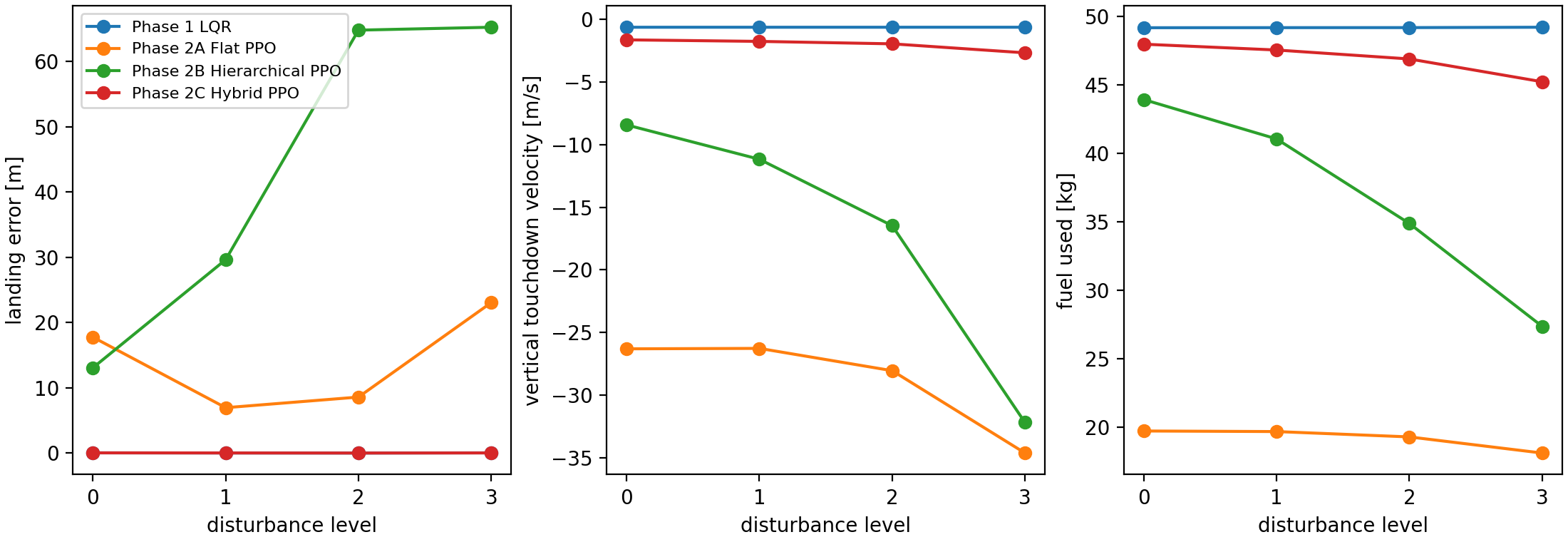
The table below compresses the saved nominal metrics and the 500-episode-per-level Monte Carlo summary. The disturbance columns report success rate by composite level. The landing-error, vertical-speed, and fuel columns use level 2 means because that is the first level where the hybrid controller stops being perfect but still retains most successes.
| Controller | Nominal | MC L0 | MC L1 | MC L2 | MC L3 | L2 error mean | L2 \(v_z\) mean | L2 fuel mean | Dominant failure |
|---|---|---|---|---|---|---|---|---|---|
| Phase 1 LQR | success | 100% | 100% | 100% | 100% | 0.026 m | -0.639 m/s | 49.2 kg | none in saved MC |
| Phase 2A Flat PPO | failure | 0% | 0% | 0% | 0% | 8.600 m | -28.048 m/s | 19.3 kg | hard touchdown, lateral miss, horizontal speed |
| Phase 2B Hierarchical PPO | failure | 0% | 0% | 0% | 0% | 64.805 m | -16.476 m/s | 34.9 kg | hard touchdown, lateral miss, attitude/rate failures |
| Phase 2C Hybrid PPO | success | 100% | 100% | 91.6% ± 2.4 pp | 0% | 0.026 m | -1.963 m/s | 46.9 kg | hard touchdown under stronger disturbance |
The hybrid controller is the first learned controller here that becomes competitive on nominal and moderate-disturbance cases, but LQR remains the strongest controller overall. The interesting result is the mechanism: the learned method improves only after the interface is shaped around the physics of the failure.
Flat PPO baseline
The first learned baseline is deliberately flat. One PPO policy sees the normalized landing observation and outputs throttle plus pitch/yaw gimbal commands. It is the cleanest RL baseline because there is no hand-designed hierarchy, no classical prior, and no privileged decomposition. That also makes it a hard learning problem: the policy must discover vertical energy management, attitude stabilization, lateral correction, and actuator timing simultaneously.
The observation is a normalized vector built from target-relative position, target-relative velocity, scalar-first quaternion, body rates, and fuel fraction. The action map was changed from a raw \([-1,1]\rightarrow[0,1]\) throttle mapping to a hover-relative throttle mapping. Without that change, early training spent too much of its capacity rediscovering a local operating point instead of learning when to brake:
observation = [
target_relative_position,
target_relative_velocity,
scalar_first_quaternion,
body_rates,
fuel_fraction,
]
action = [
hover_relative_throttle_delta,
pitch_gimbal_command,
yaw_gimbal_command,
]The reward was not left as one opaque scalar. It is decomposed into dense progress and safety terms plus terminal touchdown terms: altitude progress, lateral miss, vertical and horizontal speed, tilt, angular rate, control effort, and final success/failure criteria. This decomposition matters because the failure mode was not "PPO did nothing." The policy learned parts of the descent. The problem was joint satisfaction of all touchdown constraints.
A useful way to read the flat baseline is as a credit-assignment stress test. The same scalar action \(a_T\) must decide whether to descend, hover, or brake; at the same time, the two gimbal actions must rotate the thrust vector enough to correct lateral error without ruining vertical acceleration. The vertical acceleration channel is approximately
That approximation explains why the flat policy is brittle near touchdown. A lateral correction that increases \(\alpha\) steals a small amount of vertical thrust exactly when the policy also needs to brake. The PPO objective sees this only through delayed terminal penalties, so the policy can improve one touchdown variable while quietly worsening another.
Curriculum also mattered. Training starts with easier altitude, lateral-offset, attitude, and disturbance ranges and ramps toward the nominal evaluation regime. Wind staging is used during training but not during evaluation. The evaluation remains tied to the locked Phase 1 scenarios so comparisons do not drift while the learned policy improves.
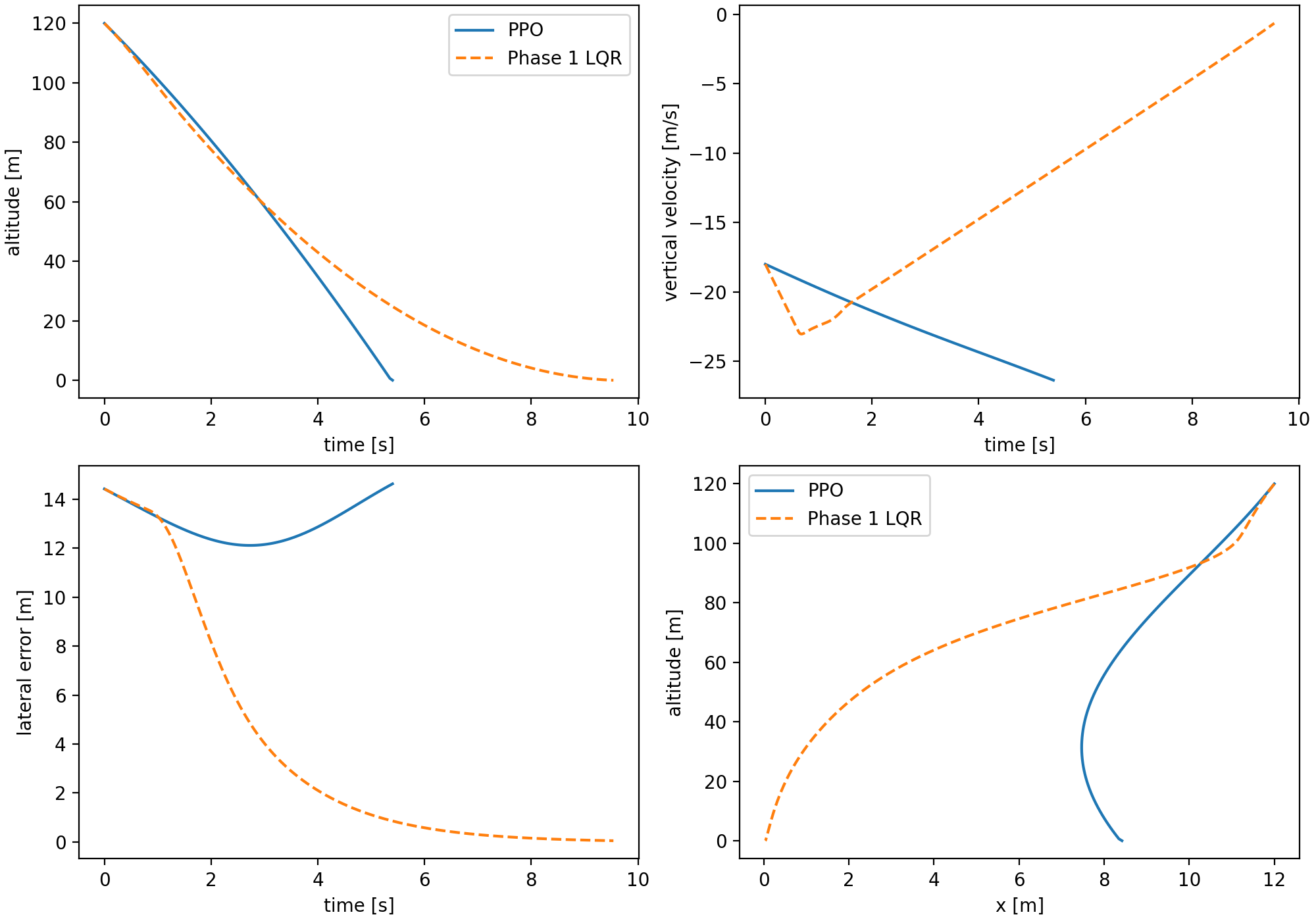
The best stabilized 50k flat PPO checkpoint still fails nominal touchdown. It reaches the ground but has large lateral error and a hard vertical touchdown. Continuing to 100k did not monotonically improve the policy; it regressed in the touchdown regime. That is one of the first useful lessons from the benchmark: more training under the same flat interface is not guaranteed to produce a safer controller when the objective couples several physical constraints.
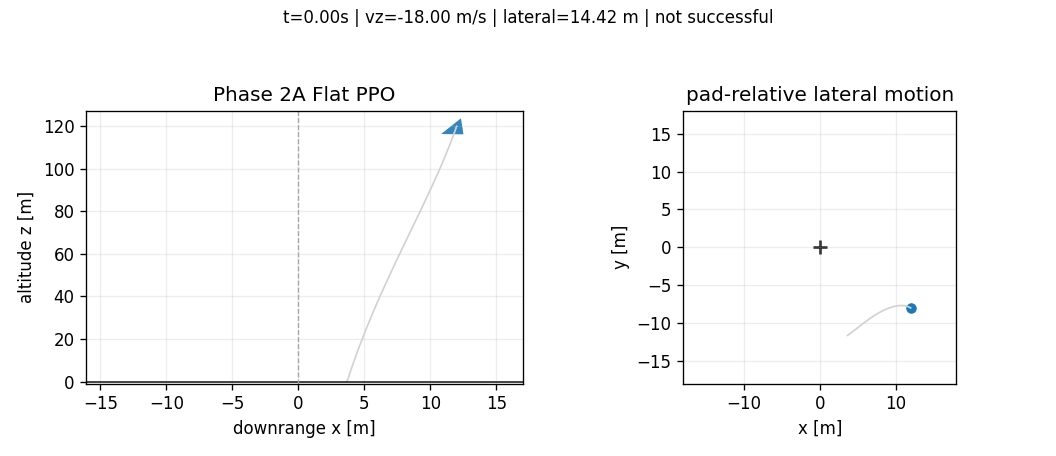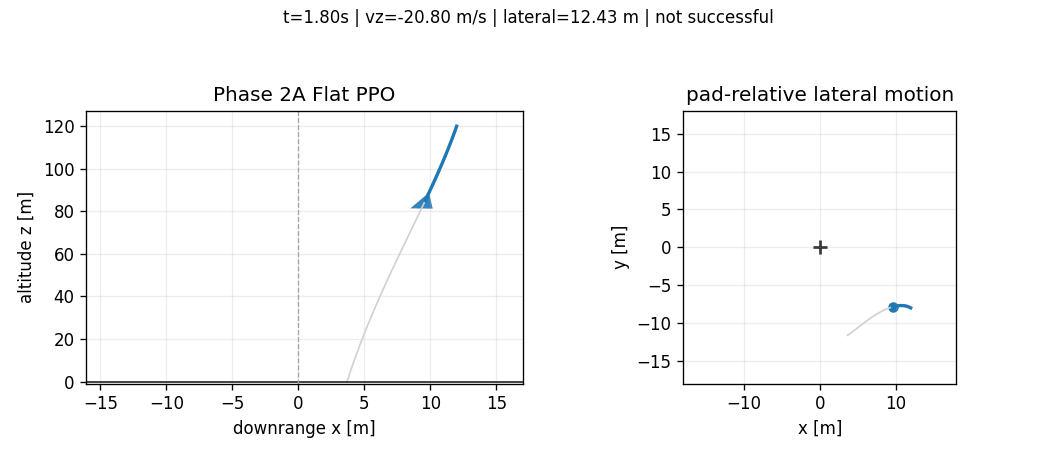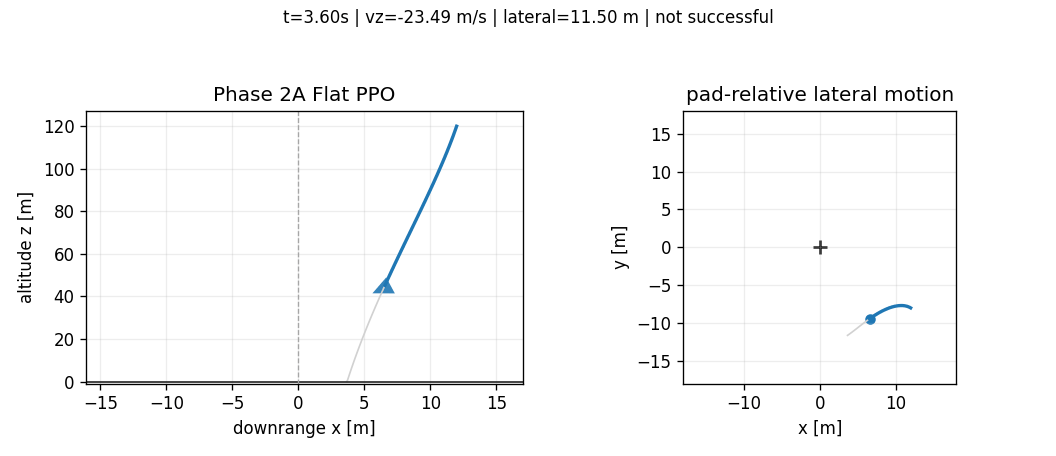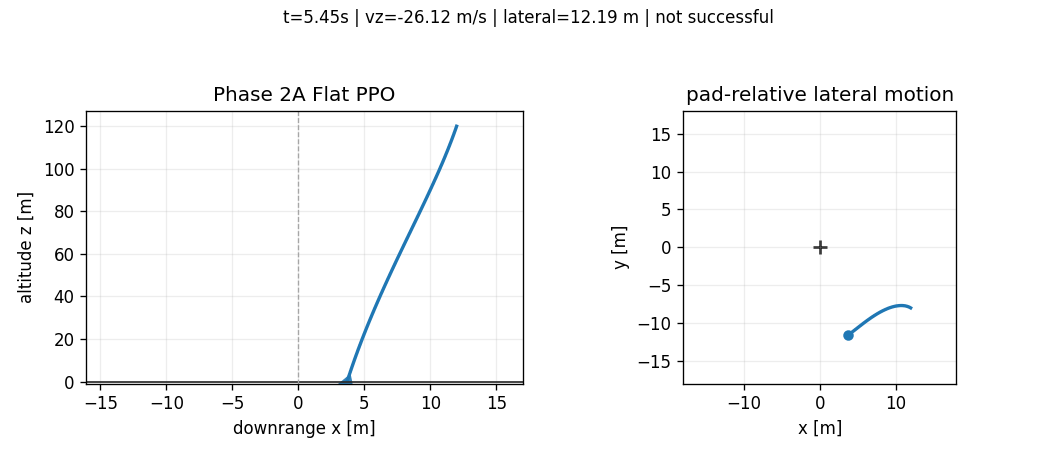
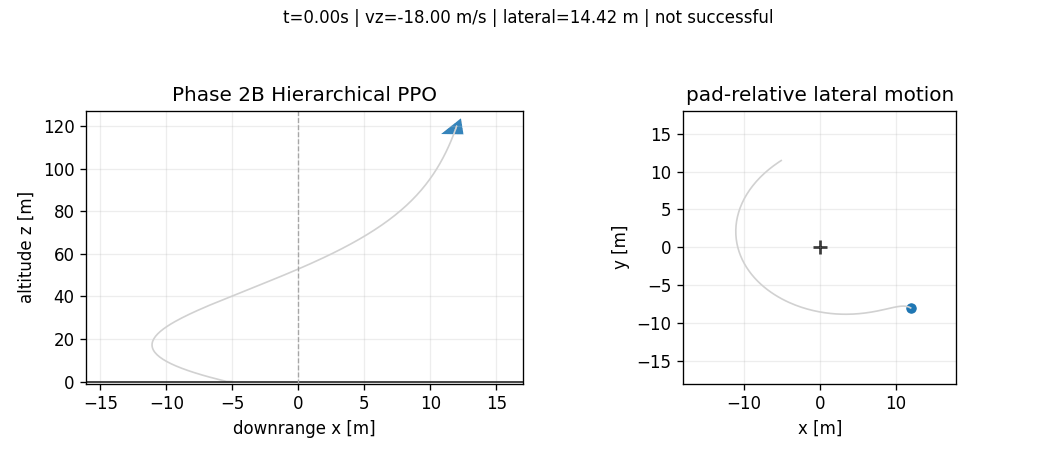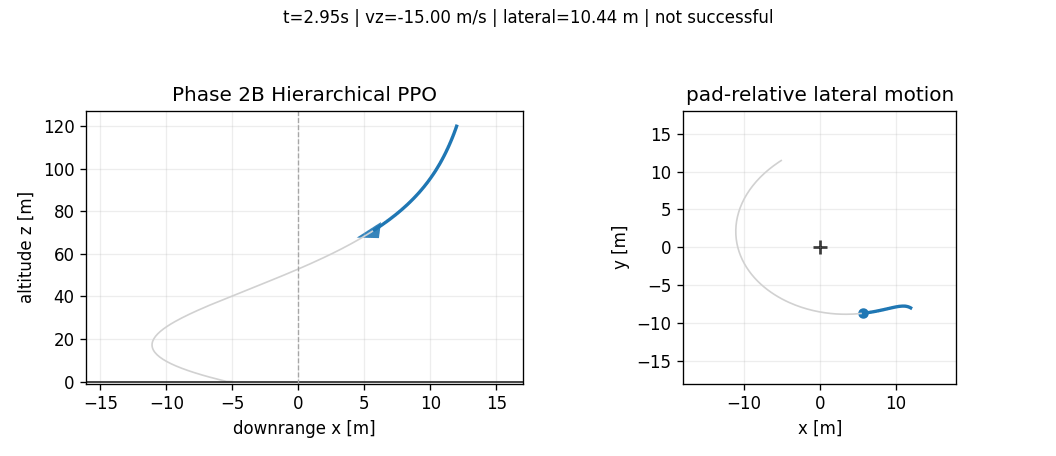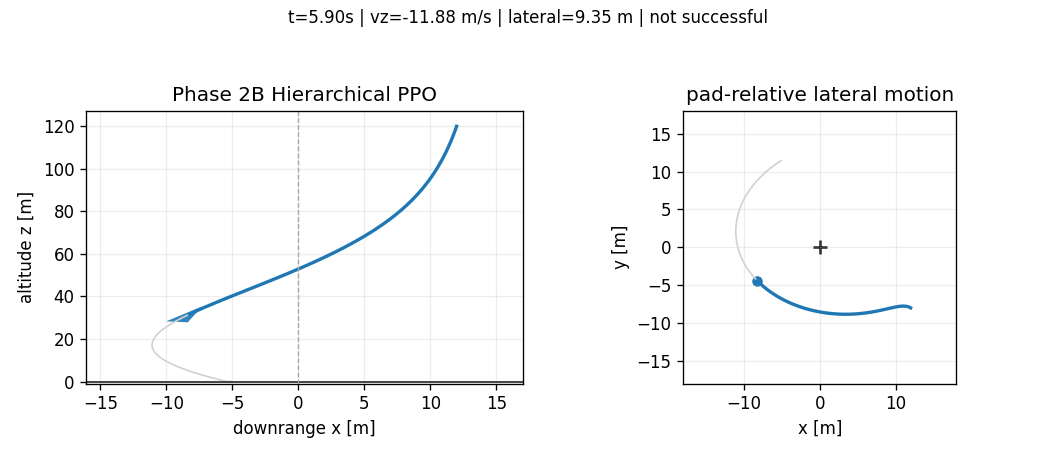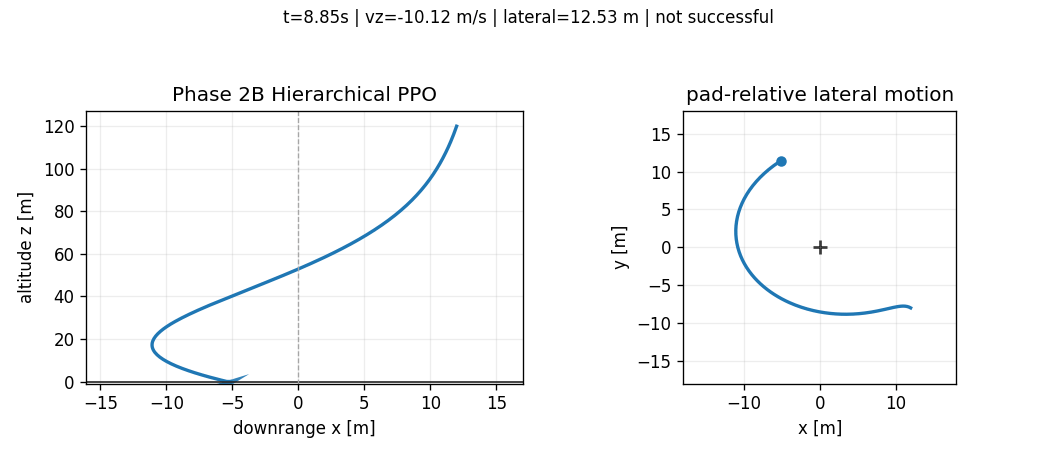
Hierarchical PPO
The hierarchical PPO phase tests a clean hypothesis: maybe the flat policy fails because the vertical and lateral-attitude problems interfere. The split is intentionally simple. A throttle policy receives only the reduced vertical-energy state \([h,v_z,m]\), while a TVC policy receives the full landing observation plus throttle context. The final controller is still evaluated in the full 6DOF simulator; the reduced-order throttle environment is a training subproblem, not a claim that the landing problem itself is one-dimensional.
This decomposition is attractive because it matches the way one might describe the task verbally: throttle manages vertical energy, TVC manages attitude and lateral motion. But the physics does not respect that separation perfectly. A throttle decision changes available time, dynamic pressure, velocity, and therefore the lateral/attitude recovery problem. A TVC decision changes attitude and thrust direction, which feeds back into vertical acceleration. The subsystems are separable for training convenience, not independent in the true dynamics.
The first pure hierarchy reached touchdown but failed on lateral and attitude metrics. Later throttle shaping improved reduced-order vertical touchdown speed; flare tracking reduced one obvious bottleneck. Adding coordination features to the TVC observation made throttle rate, vertical tracking error, flare progress, and the reference descent rate visible to the second policy. Even with those extra features, the pure frozen hierarchy did not solve touchdown.
The terminal metric penalty shows why the hierarchy was not simply "better flat PPO." The saved Phase 2B rollout reduced the vertical touchdown speed relative to Phase 2A, but paid for it with worse horizontal speed and tilt:
That number is close to the flat PPO terminal metric penalty, but the composition changed. Phase 2B made vertical speed less catastrophic and made lateral-attitude coordination more catastrophic. This is exactly the kind of diagnostic value we wanted from the hierarchy: it exposed which part of the decomposition was helping and which part was breaking the coupled landing problem.
This was a useful failure. The split improved parts of descent timing but exposed a coordination problem: a frozen throttle schedule can dominate the terminal regime before the TVC policy has enough coupled authority to recover lateral motion and attitude. The negative result justified a different next step: keep the learned decomposition where it helps, but give the TVC channel a stabilizing prior instead of asking PPO to relearn all low-level attitude behavior.
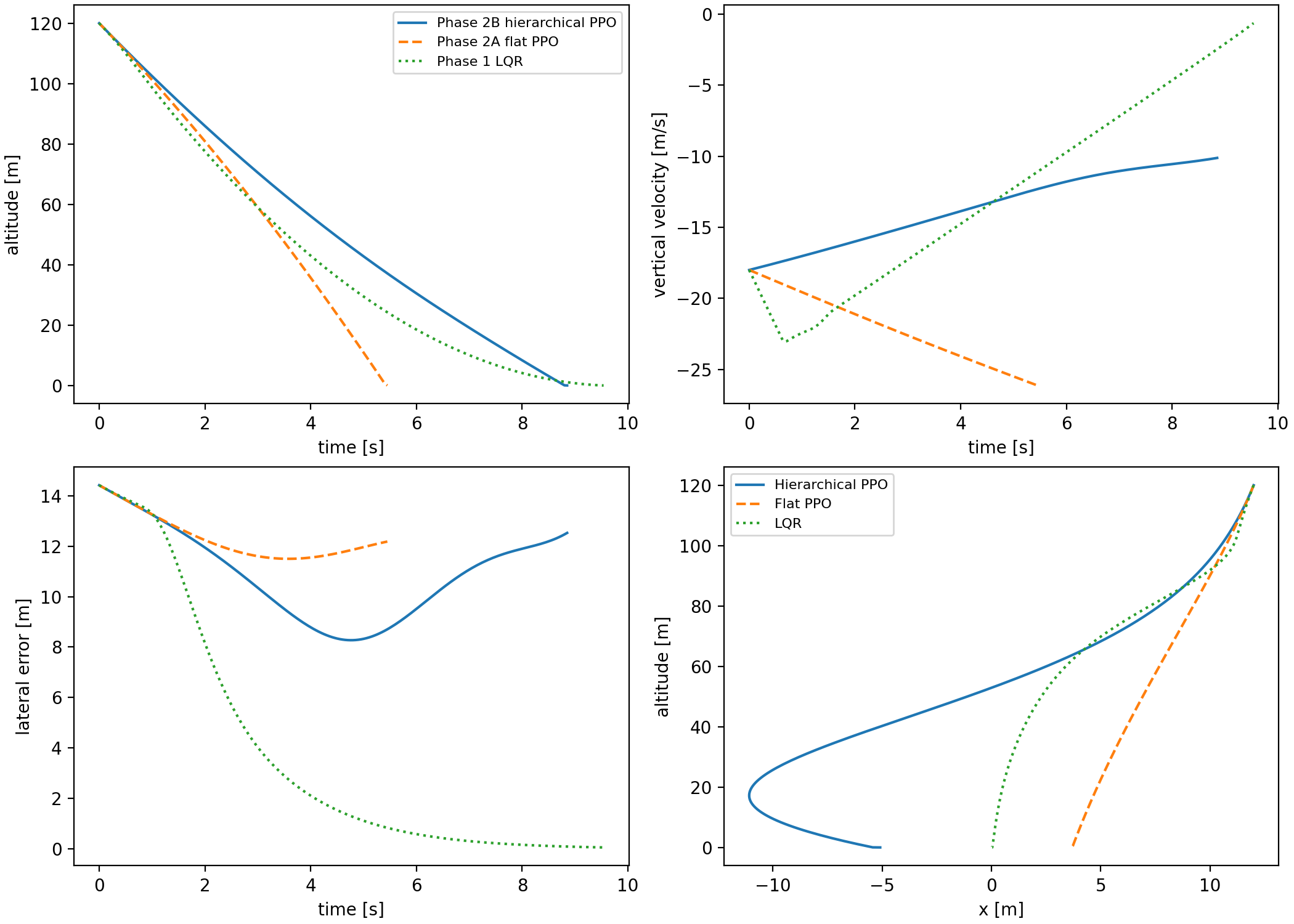
Hybrid residual PPO
The hybrid residual controller changes the scientific question. The pure hierarchy asked whether structure alone was enough. It was not. The hybrid controller asks whether learning can be useful when it is assigned a narrower and more interpretable role. PPO no longer owns the entire TVC command. It learns a bounded residual around the LQR pitch/yaw command:
More explicitly, the promoted Phase 2C controller uses a TVC-only residual policy. The residual observation concatenates the flat 14-vector, the five vertical coordination features used in Phase 2B, and the two normalized LQR gimbal commands:
That is the architectural difference from Phase 2A and Phase 2B. Phase 2A asks PPO to learn the full map from state to throttle and TVC. Phase 2B asks two PPO policies to learn throttle and TVC separately. Phase 2C asks PPO only for a bounded correction around a stabilizing gimbal prior, while throttle is handled by a learned prior plus explicit braking terms.
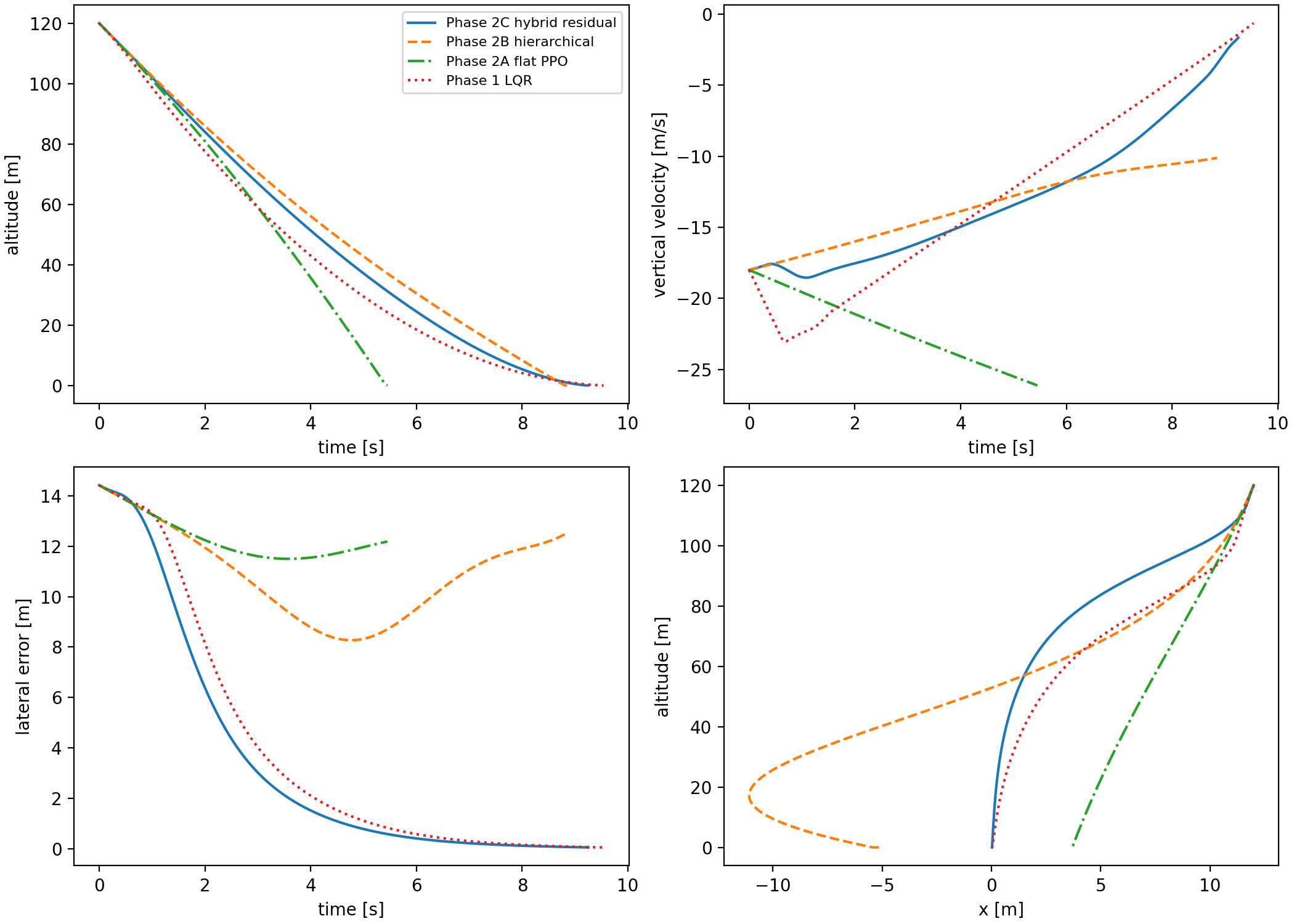
This changed the failure landscape immediately. The residual policy preserved the strong stabilizing behavior of the LQR prior while allowing the learned controller to correct small systematic errors. Horizontal speed, landing error, tilt, and angular-rate norm became very small. The remaining failure became almost entirely vertical touchdown speed.
Why vertical descent was the hard variable
By this point the benchmark had effectively separated five touchdown variables: lateral landing error, horizontal touchdown speed, tilt angle, angular-rate norm, and vertical touchdown speed. Phase 2C made the first four almost boring: landing error dropped to centimeter scale, horizontal velocity stayed far below the \(1.0\,\text{m/s}\) limit, tilt stayed far below \(10^\circ\), and angular rate stayed near zero. The one variable that refused to cooperate was vertical descent. That is why the rest of Phase 2C became less about "make PPO smarter" and more about "make the vertical braking constraint explicit enough that the controller cannot ignore it."
| Phase 2C variant | Landing error | Horizontal touchdown | Tilt | Angular rate | Vertical touchdown | Success |
|---|---|---|---|---|---|---|
| Residual baseline | 0.156 m | 0.070 m/s | 0.245 deg | 0.0038 rad/s | -10.940 m/s | false |
| Overspeed v3 baseline | 0.124 m | 0.049 m/s | 0.089 deg | 0.0020 rad/s | -4.438 m/s | false |
| Energy assist | 0.043 m | 0.042 m/s | 0.081 deg | 0.0018 rad/s | -2.475 m/s | false |
| Stopping-distance floor | 0.048 m | 0.037 m/s | 0.073 deg | 0.0018 rad/s | -1.677 m/s | true |
The residual architecture and LQR prior were already good enough for lateral-attitude control. The vertical channel needed a different intervention because it was governed by a one-dimensional energy inequality, not by small residual gimbal corrections.
The vertical channel then became a sequence of increasingly explicit prior-design experiments. A bounded learned throttle residual did not close the gap. A more touchdown-focused reduced-order throttle reward improved the reduced-order task slightly but did not move the full 6DOF controller enough. Naive altitude-gated penalties created hover or timeout behavior. Overspeed assists helped more than reward-only changes because they directly raised the throttle prior when the descent was unsafe. Brake floors improved the same idea by enforcing a smooth minimum throttle inside a near-ground overspeed condition.
The current nominal successful controller uses a stopping-distance floor. The logic is physically direct: if the current downward speed cannot be reduced to the target touchdown speed inside the remaining altitude, raise the prior throttle. The required deceleration estimate is
The floor is gated smoothly by altitude and acts as a lower bound, not a full takeover. The final prior composition is a maximum over the learned throttle prior, overspeed/energy assists, overspeed-armed brake floor, and stopping-distance floor. This is less elegant than a single end-to-end learned policy, but it is much easier to audit. Each added term answers a specific failure observed in saved rollouts.
The hybrid controller, step by step
Written as an inference-time algorithm, Phase 2C is less mysterious than the name suggests. The residual policy never receives permission to overwrite the whole controller. It can only bend a prior that already has the right stabilizing shape:
input: full 6DOF state x, previous throttle u_prev
u_lqr, delta_lqr = gain_scheduled_lqr(x)
u_learned = frozen_throttle_policy(h, vz, fuel_fraction)
c_T = coordination_features(x, u_learned, u_prev)
o_21 = concat(o_14(x), c_T, normalize(delta_lqr))
delta_res = residual_policy(o_21) * deg2rad(3.0)
delta = clip(delta_lqr + delta_res, -gimbal_limit, gimbal_limit)
du_overspeed = overspeed_assist(h, vz)
du_energy = energy_assist(h, vz)
u_brake = overspeed_brake_floor(h, vz)
u_stop = stopping_distance_floor(h, vz, m)
u = max(u_learned,
u_learned + du_overspeed + du_energy,
u_brake,
u_stop)
return clip(u, min_throttle, max_throttle), deltaThis algorithm box is also the audit trail. If the controller fails vertically, inspect the throttle prior stack. If it fails laterally or in attitude, inspect the LQR prior and residual TVC channel. The decomposition is imperfect, but it gives every failure a place to live.
| Controller | Nominal success | Landing error | Vertical touchdown | Horizontal touchdown | Tilt |
|---|---|---|---|---|---|
| Phase 1 LQR | true | 0.047 m | -0.654 m/s | 0.040 m/s | 0.111 deg |
| Phase 2A Flat PPO | false | 12.188 m | -26.116 m/s | 1.613 m/s | 4.551 deg |
| Phase 2B Hierarchical PPO | false | 12.530 m | -10.122 m/s | 8.258 m/s | 21.279 deg |
| Phase 2C Hybrid PPO | true | 0.048 m | -1.677 m/s | 0.037 m/s | 0.073 deg |
The table is generated from saved nominal metrics recorded in outputs/phase4_blog/controller_summary.json.
Energy constraint and throttle braking
The vertical failure mode eventually became the clearest part of the project. The hybrid controller had already made lateral error, horizontal touchdown speed, tilt, and angular rate small. What remained was a vertical-energy problem: the vehicle was arriving near the pad with too much downward kinetic energy for the remaining altitude.
The simplest way to see the constraint is to ignore drag and write the one-dimensional braking relation
Here \(v_{down}=\max(-v_z,0)\), \(h\) is altitude remaining, and \(v_{touch}\) is the target downward touchdown speed. This is not a full guidance law; it is a feasibility check. If \(a_{req}\) exceeds what the engine can provide after gravity, the controller is already late.
The same relation can be read as a specific-energy statement. The amount of vertical kinetic energy per unit mass that must be removed before touchdown is
For example, in the saved successful Phase 2C stopping-floor rollout, near \(h=5.02\,\text{m}\) the vehicle is still descending at \(v_{down}=6.52\,\text{m/s}\). With \(v_{touch}=0.8\,\text{m/s}\),
That \(4.16\,\text{m/s}^2\) is upward acceleration in excess of what is needed merely to cancel gravity. With mass \(m\approx1209\,\text{kg}\), gravity \(g=9.80665\,\text{m/s}^2\), and \(T_{max}=18000\,\text{N}\), the raw throttle required to meet that braking demand is
This explains why light reward changes were not enough: by the last few meters, the vehicle is not choosing between two equally easy policies. It is close to a physical throttle boundary. At \(h\approx1.95\,\text{m}\), the same saved rollout has \(v_{down}=4.61\,\text{m/s}\):
The required raw throttle is already above the actuator limit, so the implemented floor can only ask for saturation. In the logged trajectory, throttle reaches \(1.0\) near \(h\approx0.93\,\text{m}\). The stopping floor did not make the problem easy; it made the controller brake early enough that saturation near the ground became survivable instead of hopeless.
The final throttle-prior stack has three conceptually different braking terms. The overspeed assist responds to velocity relative to the flare reference. The energy assist responds to excess vertical kinetic energy above a braking envelope. The stopping-distance floor asks whether the remaining altitude is sufficient to shed the current downward speed:
The energy assist uses the reference envelope
The \(gh\) terms cancel algebraically, but keeping them in the definition is useful because the controller design is really about vertical specific energy, not just speed. The RL-facing assist then turns that scalar into a gated throttle increment:
With \(a_{brake}=1.5\,\text{m/s}^2\), the same \(h=5.02\,\text{m}\) point has \(v_{env}\approx3.96\,\text{m/s}\). The actual \(6.52\,\text{m/s}\) descent therefore carries roughly \(\frac{1}{2}(6.52^2-3.96^2)\approx13.4\,\text{J/kg}\) of excess kinetic energy above the intended braking envelope. That is exactly the kind of scalar signal the energy assist was designed to expose.
With the Phase 2C energy settings \(h_E=35\,\text{m}\), \(p_E=1.5\), \(e_{scale}=40\,\text{J/kg}\), \(p_{shape}=0.8\), and \(\Delta u_{E,\max}=0.10\), that same point gives
That number is small enough not to replace the learned throttle prior, but large enough to matter when the vehicle is near the actuator boundary. This is the core difference between "reward asks the policy to care about energy" and "the controller interface injects an energy-aware throttle prior." The former must be discovered through PPO updates; the latter is present at inference time whenever the saved rollout violates the braking envelope.
The sweep history tells the same story numerically. The first overspeed-assist sweep started from `overspeed_assist_v3_baseline`, which touched down at \(-4.438\,\text{m/s}\). Increasing the late-stage extra assist improved this to \(-4.315\,\text{m/s}\). Widening the late-stage subzone to \(3.5\,\text{m}\) and using \(0.08\) extra throttle improved it again to \(-4.263\,\text{m/s}\). Making the outer assist more aggressive regressed to \(-4.463\,\text{m/s}\), which suggested that "more throttle sooner" was not the right one-line answer.
A second focused sweep kept the outer gate fixed and varied only the local late-flare shape. The best candidate was the blended setting: \(4.0\,\text{m}\) late-stage altitude and \(0.10\) extra throttle, reaching \(-4.114\,\text{m/s}\). That was directionally correct but still a hard touchdown. The later brake-floor and energy-assist passes moved the vertical channel much more:
| Prior family | Vertical touchdown | Horizontal touchdown | Landing error | Result |
|---|---|---|---|---|
| Overspeed v3 baseline | -4.438 m/s | 0.049 m/s | 0.124 m | hard touchdown |
| Focused blended late flare | -4.114 m/s | 0.049 m/s | 0.121 m | hard touchdown |
| Overspeed brake floor | -4.069 m/s | 0.045 m/s | 0.107 m | hard touchdown |
| Energy assist | -2.475 m/s | 0.042 m/s | 0.043 m | hard touchdown |
| Stopping-distance floor | -1.677 m/s | 0.037 m/s | 0.048 m | success |
The important point is not that the final controller found a magic throttle value. The important point is that each prior encoded a sharper form of the same physical constraint. Overspeed assist says "you are faster than the flare schedule." Energy assist says "you carry too much vertical kinetic energy." Stopping-distance floor says "given the altitude left, here is the minimum thrust needed to make the target touchdown speed even possible." The last statement is the most directly connected to the failure condition, and that is why it finally moved the nominal rollout across the locked success threshold.
What actually made it work
The saved Phase 2C variants are not a perfect factorial ablation study, but they are enough to identify the mechanism. The big jump did not come from training longer or adding a larger neural network. It came from changing the interface: the lateral-attitude problem was handed to an LQR prior plus a bounded residual, while the vertical channel received increasingly direct braking structure.
| Variant | What changed | Landing error | Horizontal touchdown | Vertical touchdown | Result |
|---|---|---|---|---|---|
| Residual baseline | LQR TVC prior plus bounded residual PPO; learned throttle prior unchanged | 0.156 m | 0.070 m/s | -10.944 m/s | hard touchdown |
| Overspeed assist | Add terminal throttle assist when descent is faster than the flare schedule | 0.124 m | 0.049 m/s | -4.438 m/s | hard touchdown |
| Brake floor | Add an overspeed-armed minimum throttle floor near the ground | 0.107 m | 0.045 m/s | -4.069 m/s | hard touchdown |
| Energy assist | Add throttle based on excess vertical specific energy | 0.043 m | 0.042 m/s | -2.475 m/s | hard touchdown |
| Stopping-distance floor | Add a lower bound from the deceleration needed to reach the touchdown-speed target | 0.048 m | 0.037 m/s | -1.677 m/s | success |
The LQR prior and residual policy made the lateral variables small, but they did not solve vertical energy. Overspeed and brake-floor logic helped, but the controller was still late. Energy assist moved the touchdown speed close to the threshold. The stopping-distance floor finally bound the prior to the exact question that decides the terminal failure: can the current downward speed be reduced inside the altitude that remains?
Where it breaks
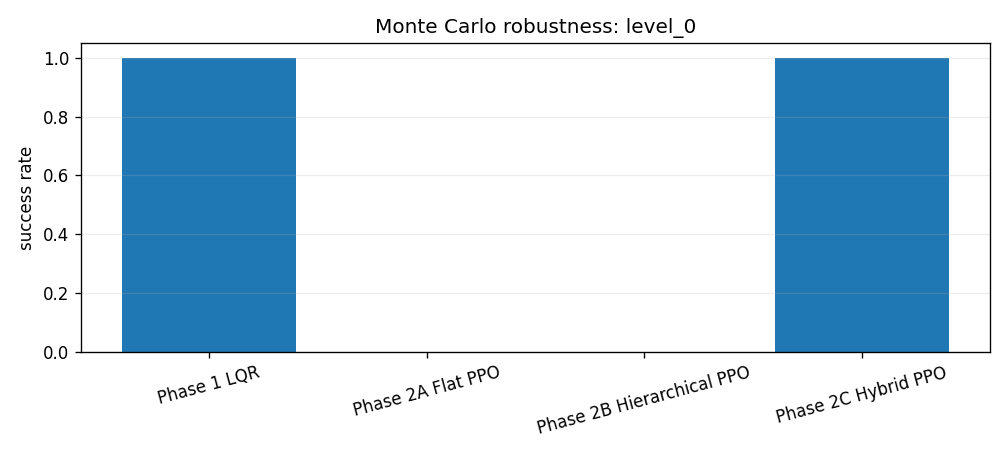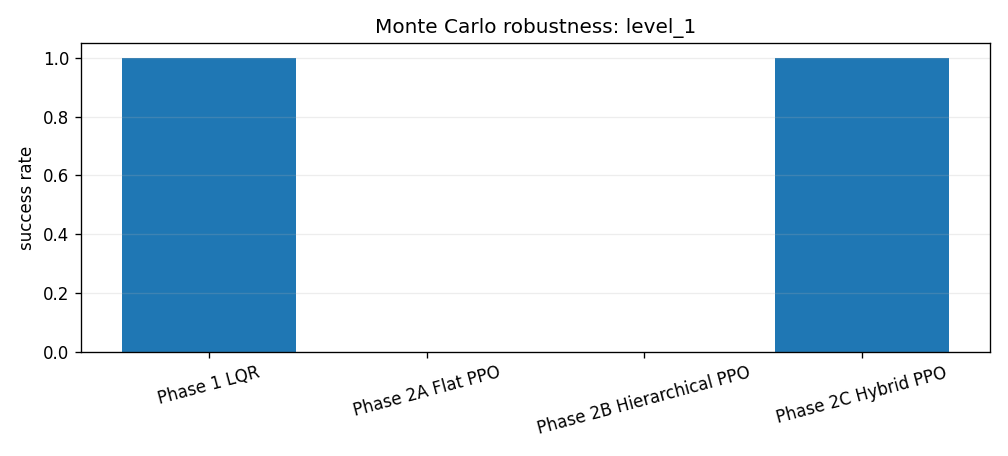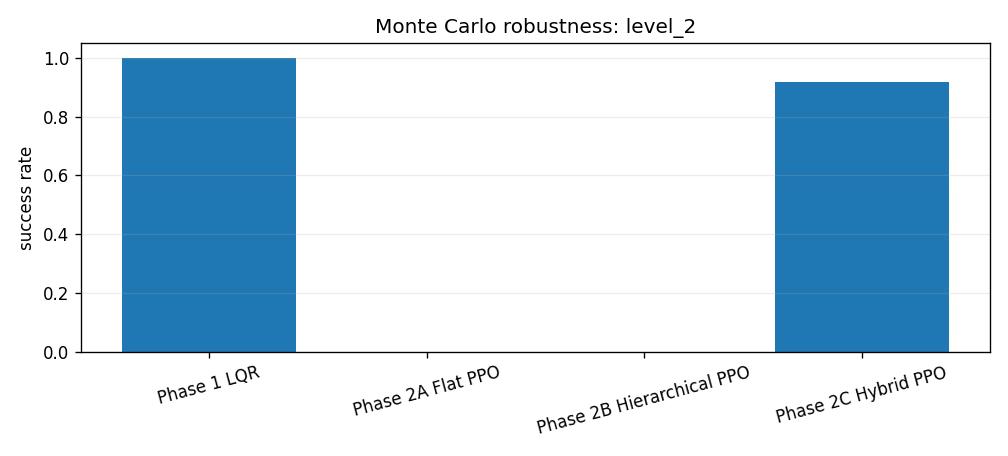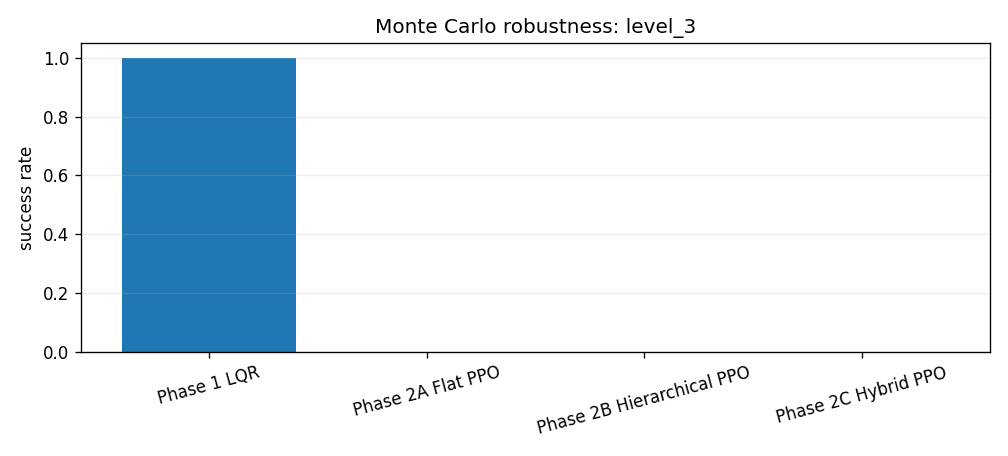
The Phase 3 evaluation runs four controllers across four composite disturbance levels with 500 episodes per level. Each level bundles wind, gust, and thrust-misalignment settings. The point is not to hide failures behind one nominal trace. The point is to make robustness visible.
This distinction matters because the nominal result and the robustness result answer different questions. The nominal Phase 2C stopping-floor controller is the first saved learned-controller path that satisfies the locked touchdown criteria in the fixed nominal scenario. The Monte Carlo evaluation asks whether that success survives randomized episodes under disturbance. It does not make the learned controller more realistic than the model permits; it makes the limitations measurable.
The saved Monte Carlo summary reports success rates, landing error, vertical touchdown velocity, tilt, and fuel use by controller and disturbance level. LQR remains extremely strong. Flat PPO and pure hierarchy do not become safe under disturbance. Hybrid residual PPO is much better than the other learned baselines, but the robustness plot still shows why the classical baseline remains a serious comparator rather than a ceremonial control group.
The hybrid result has a clear cliff. It succeeds in all 500 episodes at levels 0 and 1, succeeds in 458 of 500 episodes at level 2, and fails all 500 level-3 episodes by hard touchdown. Using the binomial approximation above, the level-2 success rate is \(91.6\%\pm2.4\) percentage points. That is strong enough to show the residual-plus-prior interface is not just a nominal trick, but not strong enough to claim broad robustness.
There are also sensitivity questions that we cannot yet answer for the learned controllers. Phase 1 has saved mass and disturbance sweeps, but the full learned-controller stack has not yet been rerun across a broad vehicle-mass grid, multi-seed training grid, stopping-floor parameter grid, or domain-randomized training regime. Those are not cosmetic additions. They are the next tests that would decide whether Phase 2C is a robust control design or a strong artifact-specific controller.
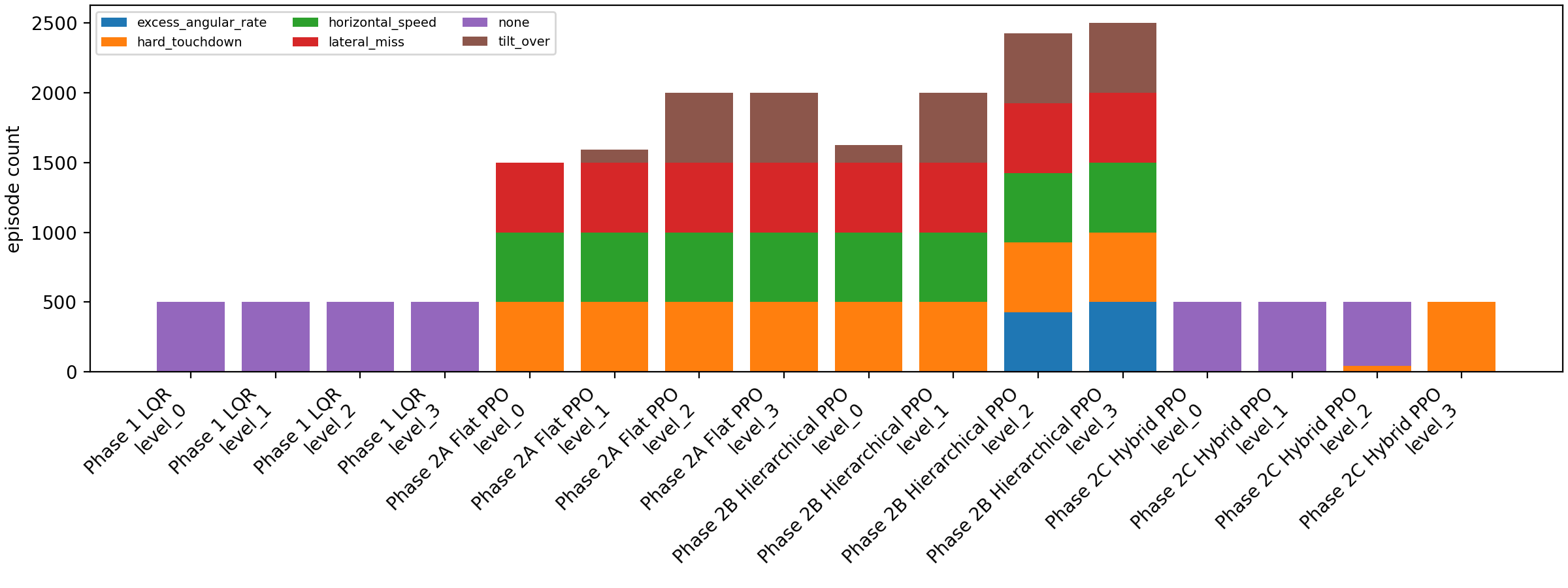
The failures were the signal
Flat PPO failed broadly: hard touchdown, lateral miss, and horizontal-speed failures appeared together. That pointed away from "just tune touchdown reward" and toward a decomposition problem. Pure hierarchy changed the failure composition but did not solve it: vertical speed improved relative to flat PPO, while lateral-attitude metrics became worse. That pointed toward coordination failure between a frozen throttle policy and the TVC policy. Phase 2C then made lateral-attitude behavior small enough that the remaining error was almost purely vertical, which pointed toward energy-aware throttle priors.
The failure list below is therefore a design history:
- Stronger lateral reward shaping did not make pure hierarchy land safely; it often degraded the full rollout.
- Making TVC starts easier through a near-pad curriculum did not solve the terminal coordination problem.
- Adding coordination features to the TVC observation improved observability but did not create enough coupling by itself.
- A bounded learned throttle residual around the current throttle prior preserved lateral quality but worsened vertical touchdown speed.
- A weak physics-guided throttle floor was mostly neutral because it did not bind over the existing learned-plus-assisted prior.
- Reward-only near-ground refinements produced much smaller improvements than structured prior-side braking.
The common pattern is that reward shaping helped only when the policy interface already made the right behavior discoverable. When the interface was wrong, heavier penalties made policies exploit the wrong part of the task: hover instead of descend, reduce one metric while sacrificing another, or preserve attitude while still touching down too hard. The strongest improvements came from making the control structure match the failure mode: LQR prior for lateral-attitude stabilization, and physically interpretable throttle floors for terminal vertical braking.
The useful pattern was not "PPO beats control." The useful pattern was "PPO works best here when the interface gives it a stabilizing prior and leaves it a bounded, interpretable correction problem."
What would make this stronger
The simulator is intentionally modest about realism, but strict about control-relevant structure: variable mass, quaternion attitude, lateral-attitude coupling, TVC limits, atmosphere, aerodynamics, and disturbances stay in the loop.
The core lesson is that problem decomposition matters more than just adding a learned policy. Flat PPO struggled because the task couples vertical energy, lateral motion, and attitude. Pure hierarchy helped isolate responsibilities but made terminal coordination brittle. Hybrid residual PPO worked because the classical prior handled stabilizing structure while learning focused on residual corrections and vertical-prior shaping.
The limitations are substantial. The simulator does not model exact Falcon 9 geometry, mission operations, entry dynamics, boostback, landing-burn mode logic, high-fidelity aerodynamics, engine startup transients, landing-leg contact dynamics, or SpaceX flight software. Yaw is underactuated in the current single-centered-engine model and is excluded from success criteria. The current learned-controller results are also still seed- and artifact-specific; broader training sweeps would be needed before making stronger claims about algorithmic superiority.
The next evidence gap
The next evidence gap is breadth. Reusable-launch-vehicle guidance and control, residual reinforcement learning, hierarchical RL, and safety-filtered learning all touch this project from different directions, but the strongest version of the claim would need broader seed sweeps, cleaner ablations, and learned-controller sensitivity runs. The claim should stay narrow even after those additions. This is a Falcon 9-inspired control benchmark with simplified atmosphere and aerodynamics, not an operational landing-burn reconstruction. The most useful extensions are therefore the ones that change the control question rather than the ones that merely add detail: TVLQR, actuator dynamics, richer wind fields, domain randomization, policy distillation, and an explicit phase-based terminal-guidance layer.
Future work should therefore move in two directions at once. The physics model should add only realism that changes the control question in a meaningful way: better aero, explicit yaw actuation, sensor delay/noise in the controller loop, actuator dynamics, and phase-based terminal guidance. The learning side should focus less on unconstrained end-to-end policies and more on interfaces that preserve auditability: residual policies, safety filters, structured priors, and evaluation protocols that make failures harder to hide.